

Transformers In Self and Cross Attention
Initially the transformers began for sequential inputs only where they are later encoded with embeddings. The original paper can be referenced here,
The most General Architecture of a Transformer consists of a encoder and decoder model as discused in the Attention article that I wrote earlier.
Both the encoder and decoder has a set of layers where the first layer consists of the multi-head attention model, which is followed by the layer normalization node.
The attention is basically mapping a query and a set of key-value pairs to an output, where all three are just verctors. There are two type of attnetion functionality used in the Transformer models:
1. Scaled Dot Produt Attention
2. Multi-Head Attention
The input in Language Processing has the input nodes along with a extra node called the EOS(end of sentence) at the end. These inputs are then embedded with some associated weights by passing through an Activation Function. The multihead Attention Node passes 1 for each input and 0 for the other inputs parallelly and calculates all the following values that needs to be calculated ahead in the model. The weights associated with the activation function for each and every word are same and also are learnable parameter. Now the word order is also important while embedding the input. This is where the Positional Embedding comes into picture along with the word embeddings. The positional embedding values comes from the sine and cosine values that acts as vectors as well and form a sequence themselves. The positional embeddings are added with the word embeddings
Now comes the mechanism for associating words with other words with the help of Self Attention. This helps to associate words with other words and even itself. This information determines how the tranformer encodes every word.
So to use the Attention mechanism the Queries and Keys are calculated with learnable weight parameters. The weights associated to calculate the Queries and Keys are same respectively while also being learnable parameters. Here on onwards the scaled Dot Product attention is then later calculated with the given formula below.
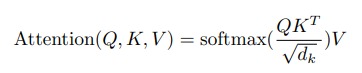
The Scaled Dot product outcomes are then calculated for the queries of each and every word with the keys of every other word along with the word itself. The outcomes are then passed through softmax functions to see the probability or percentage of similarity where they are also called values. These values are what that helps to give words context. The additive result for the values give meaning to more complex statements. The Self Attention nodes have common learnable parameters for respective Keys, Queries and Values. Multiple Self Attention Nodes can be stacked upon each other with their own unique weights form the Multi Head Attention unit. The Simple transformers also have another unit called Residual connetion where the positional embeddings are directly added to the result without going through the attention as it is easy to train having less learnable parameters.
Now in Language processing the other half of encoder is the Decoder as discussed before in earlier articles. The decoder usually begins with EOS(End of Sentence) or even SOS(Start of Sentence). The Encodings of the sentence is calculated similarly as the encoder with just EOS in it. The positional embeddings are also included here in the encoding. Similarly the Query, Key and Value of the EOS is also calucalated similaryly sa done in Encoder. The Set of weights or learnable parameters used in the decoder or the learnable parameters are all different fromt he ones used in the encoder. The residual connection is also used here.
While translation the input and output sentences also need to be kept track of their connection.
The EOS token’s Query is then calculated. The keys of each word in the encoder result into scaled dot products giving out some values which in turn give out softmax percentages. The scaled percentage values of the input words are then added to get the encoder-decoder attention values. Even at this point there is a residual connection node for ease of computation. Now for each and every translation for the words are then compared to the inputs using the softmax outputs after calculating the encoding containg all the embeddings as performed for EOS earlier, with the same set of weights used for EOS(learnable parameters). More residual connections are used here. Once the initial translation is done the final output is EOS denoting completion of the translation.