

Deep Convolutional GAN
Implementing a Deep Convolutional GAN where we are trying to generate house numbers which are supposed to look as realistic as possible.The DCGAN architecture was first explored in 2016 and has seen impressive results in generating new images; you can read the original paper, here
import matplotlib.pyplot as plt
import numpy as np
import pickle as pkl
import torch
from torchvision import datasets
from torchvision import transforms
import torch.nn as nn
import torch.nn.functional as F
%matplotlib inline
The above imports are the estimated imports that we usually require in our Notebooks. There might be more in along the way which we will import as we move forward.
Get the Data
#define the transformations to persform on the images
transform = transforms.ToTensor()
# grab the SVHN training data
dcgan_train = datasets.SVHN(root='data/',split='train', download=True, transform=transform)
# batch size and num workers
batch_size = 128
num_workers = 0
train_loader = torch.utils.data.DataLoader(dataset=dcgan_train,
batch_size=batch_size,
shuffle=True,
num_workers=num_workers)
Visulalization of Data.
Before we move along we need to see the data that we just grabbed. To check whether the data looks good to move along. Also make sure the data we are going to work with are all of same dimensions i.e., 32x32x3 where 3 is the depth of each of the image(as they are RGB images) that we grab from our dataset. Also we can see that there is a numerical value associated with each of the image.
# grab one batch of image and label from the loader
dataiter = iter(train_loader)
images, labels = dataiter.next()
# View 20 images within the batch
fig = plt.figure(figsize=(25, 4))
plot_size=20
for idx in np.arange(plot_size):
ax = fig.add_subplot(2,plot_size/2, idx+1,xticks=[], yticks=[])
ax.imshow(np.transpose(images[idx], (1,2,0)))

Preprocessing the data
Scaling the data so that the distribution of data in the image lies betwenn -1 to 1. We do this as the output layer of the generator is a tanh function which gives output image containing values that lies between -1 and 1 so this corresponds the data accordingly.
def preprocess_scaling(x, feature_range = (-1,1)):
'''Helper function to scale the images from -1 to 1.
where -1 to 1 is the feature range where the features of the images lies in.'''
min, max = feature_range
x = x*(max-min)+min
return x
img = images[0]
print("Max:",img.max(),"\nMin:",img.min())
print("-------------")
scaled_img = preprocess_scaling(img)
print("Max:",scaled_img.max(),"\nMin:",scaled_img.min())
Max: tensor(0.6314)
Min: tensor(0.0706)
-------------
Max: tensor(0.2627)
Min: tensor(-0.8588)
Model Definition
Discriminator
The discriminator takes a input tensor images of 32x32x3 dims. It comprises of few convolutional layer Along with a fully connected layer at the end for output where we also apply the sigmoid which gives an output of 0 or 1 denoting fake or real image respectively Layers I use here are:
Depths of the convolutional layer:
-
32 Initial
-
64 Next
- 128 Last
-
We also are using Batch-normalization for the network outputs. The batch norm is applied to all layers except the first convolutional layer and the last sigmoid layer.
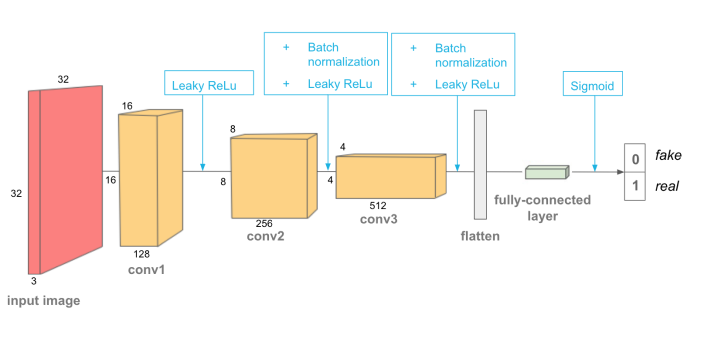
Now there is helper function that we are using to create the convolutional layers as there are conv layers that sometimes uses batch-normalization and sometimes doesn’t.
def conv(input_depth, output_depth, kernel_size, stride=2, padding=1, batch_norm=True):
"""Creates convolutional layers along with batch normalization as per
requirement. Optional is the batch normalization"""
layers = []
convLayer = nn.Conv2d(input_depth,
output_depth,
kernel_size,
stride,
padding,
bias=False)
# add the conv layer to the list "layers" by appending to it.
layers.append(convLayer)
if batch_norm:
layers.append(nn.BatchNorm2d(output_depth))
# return the sequential of the above list:
return nn.Sequential(*layers)
Discrminator Class Definition
class Discriminator(nn.Module):
def __init__(self, conv_dim = 32):
super(Discriminator, self).__init__()
# initial saves
self.conv_dim = conv_dim
# First conv layer - No Batch Norm:
self.conv1 = conv(3, conv_dim, 4, batch_norm=False)
# Second conv layer - With batch_norm:
self.conv2 = conv(conv_dim, conv_dim*2, 4)
# Third conv layer - With batch_norm:
self.conv3 = conv(conv_dim*2, conv_dim*4, 4)
# fully connected layer:
self.fc1 = nn.Linear(conv_dim*4*4*4, 1)
def forward(self, x):
# all hidden layer + leaky relu activation
out = F.leaky_relu(self.conv1(x), 0.2)
out = F.leaky_relu(self.conv2(out), 0.2)
out = F.leaky_relu(self.conv3(out), 0.2)
#flatten
out = out.view(-1, self.conv_dim*4*4*4)
#final output layer
out = self.fc1(out)
return out
Generator
The discriminator was built so as to downsample the image. Now we will have to create the generator so as to upsample the image. To downsample we simply used Convolutional layers, so to upscale a image from a some random noise we would have to use transpose Convolutional layers.
Infact even here we use a fully connected layer first before using the transpose convolutional layers.Similarly we also double the width and halve the depth of the transpose conv layers.
Also we apply batch normalization to all the hidden layers except the last one, where we use tanh instead.
def deconv(input_depth, output_depth, kernel_size, stride=2, padding=1, batch_norm=True):
"""Creates a transposed-convolutional layer, with optional batch normalization.
"""
layers = []
transpose_conv_layer = nn.ConvTranspose2d(input_depth,
output_depth,
kernel_size,
stride,
padding,
bias=False)
layers.append(transpose_conv_layer)
if batch_norm:
#append batch norm layer.
layers.append(nn.BatchNorm2d(output_depth))
return nn.Sequential(*layers)
Generator Class Definition
class Generator(nn.Module):
def __init__(self, z_size, conv_dim=32):
super(Generator, self).__init__()
# save the required data first
self.conv_dim = conv_dim
# first, fully connected layer
self.fc = nn.Linear(z_size, conv_dim*4*4*4)
# hidden layers now:
self.tconv1 = deconv(conv_dim*4, conv_dim*2, 4)
self.tconv2 = deconv(conv_dim*2, conv_dim, 4)
self.tconv3 = deconv(conv_dim, 3, 4, batch_norm=False)
def forward(self, x):
out = self.fc(x)
out = out.view(-1, self.conv_dim*4, 4, 4)
# hidden transpose convolutional layers
out = F.relu(self.tconv1(out))
out = F.relu(self.tconv2(out))
# last tconv layer and the tanh activation
out = self.tconv3(out)
out = F.tanh(out)
return out
Now that everything is defined and the whole structural build is complete of the layers of the network, lets make sure of the hyperparameters we could use in the network to make it work for our business problem
Network Build:
conv_dim = 32
z_size = 100
# define discriminator and generator
D = Discriminator(conv_dim)
G = Generator(z_size=z_size, conv_dim=conv_dim)
print(D)
print()
print(G)
Discriminator(
(conv1): Sequential(
(0): Conv2d(3, 32, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
)
(conv2): Sequential(
(0): Conv2d(32, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(conv3): Sequential(
(0): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(fc1): Linear(in_features=2048, out_features=1, bias=True)
)
Generator(
(fc): Linear(in_features=100, out_features=2048, bias=True)
(tconv1): Sequential(
(0): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(tconv2): Sequential(
(0): ConvTranspose2d(64, 32, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(tconv3): Sequential(
(0): ConvTranspose2d(32, 3, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
)
)
GPU Training
train_on_gpu = torch.cuda.is_available()
if train_on_gpu:
G.cuda()
D.cuda()
print("Using GPU")
else:
print("Using CPU")
Using GPU
Loss
Ok Now its time to check the losses for both discriminator and Generator.
Discriminator Losses
- Loss of Discrmintor(d_loss) is the sum of both loss from real image and loss from fake image:
d_loss = d_real_loss + d_fake_loss.- this is the loss from the discriminator from trying to classify the images to real and fake by giving output 1 and 0
Generator Losses
- The generator loss is basically the loss while trying to make the image look realistic i.e., having values in the images that it generates within the disribution of the training images.
- The main target of the generator is to make the
D(fake_images)as 1.
def real_loss(D_output, smooth=False):
batch_size = D_output.size(0)
if smooth:
labels = torch.ones(batch_size)*0.9
else:
labels = torch.ones(batch_size)
if train_on_gpu:
labels = labels.cuda()
# binary cross entropy with logit loss
criterion = nn.BCEWithLogitsLoss()
# calculate loss
loss = criterion(D_output.squeeze(), labels)
return loss
def fake_loss(D_output):
batch_size = D_output.size(0)
labels = torch.zeros(batch_size)
if train_on_gpu:
labels = labels.cuda()
criterion = nn.BCEWithLogitsLoss()
# calculate loss
loss = criterion(D_output.squeeze(),labels)
return loss
Optimizers
I will use ADAM Optimization for this scenario. One can always try other options to optimize the training and get better results.
import torch.optim as optim
# params
lr = 0.0002
beta1 = 0.5
beta2 = 0.999
d_optimizer = optim.Adam(D.parameters(), lr, [beta1, beta2])
g_optimizer = optim.Adam(G.parameters(), lr, [beta1, beta2])
Training The Model
Training the model involves alternating between training the discriminator and the generator.
Discriminator Training
Compute the discriminator loss on real images. Generate fake images Compute the discriminator loss on fake images. Add up the real and fake loss Perform backpropagation + an optimization step to update the discriminator’s weights
Generator Training
Generate the fake images Compute the discriminator loss on fake images, using flipped labels! Perform Backpropagation + an optimization step to update the generator’s weights
# Training Code
import pickle as pkl
# hyperparameters
num_epochs = 50
# keep track of loss and generated , fake samples
samples = []
losses = []
print_every = 300
sample_size = 16
fixed_z = np.random.uniform(-1, 1, size=(sample_size, z_size))
fixed_z = torch.from_numpy(fixed_z).float()
for epoch in range(num_epochs):
for batch_i, (real_images, _) in enumerate(train_loader):
batch_size = real_images.size(0)
# always scale images before training if not done already:
real_images = preprocess_scaling(real_images)
# ============================================
# TRAIN THE DISCRIMINATOR
# ============================================
d_optimizer.zero_grad()
# Training with Real Imgaes.
if train_on_gpu:
real_images = real_images.cuda()
D_real = D(real_images)
d_real_loss = real_loss(D_real)
# Train with fake images
# Generate fake Images
z = np.random.uniform(-1,1,size=(batch_size,z_size))
z = torch.from_numpy(z).float()
# move to GPU
if train_on_gpu:
z = z.cuda()
fake_images = G(z)
# Compute the discriminator losses on fake images
D_fake = D(fake_images)
d_fake_loss = fake_loss(D_fake)
d_loss = d_real_loss+d_fake_loss
d_loss.backward()
d_optimizer.step()
# =========================================
# TRAIN THE GENERATOR
# =========================================
g_optimizer.zero_grad()
# Generate fake images
z = np.random.uniform(-1, 1, size=(batch_size, z_size))
z = torch.from_numpy(z).float()
if train_on_gpu:
z = z.cuda()
fake_images = G(z)
# Compute the discriminator losses on fake images
# using flipped labels!
D_fake = D(fake_images)
g_loss = real_loss(D_fake)
# Run backprop and optimizer step
g_loss.backward()
g_optimizer.step()
if batch_i % print_every == 0:
# append discriminator loss and generator loss
losses.append((d_loss.item(), g_loss.item()))
# print discriminator and generator loss
print('Epoch [{:5d}/{:5d}] | d_loss: {:6.4f} | g_loss: {:6.4f}'.format(
epoch+1, num_epochs, d_loss.item(), g_loss.item()))
G.eval() # for generating samples
if train_on_gpu:
fixed_z = fixed_z.cuda()
samples_z = G(fixed_z)
samples.append(samples_z)
G.train() # back to training mode
# Save training generator samples
with open('train_samples.pkl', 'wb') as f:
pkl.dump(samples, f)
Epoch [ 1/ 50] | d_loss: 1.4261 | g_loss: 0.8809
Epoch [ 1/ 50] | d_loss: 0.0687 | g_loss: 4.2176
Epoch [ 2/ 50] | d_loss: 0.6554 | g_loss: 2.2066
Epoch [ 2/ 50] | d_loss: 0.5293 | g_loss: 1.8647
Epoch [ 3/ 50] | d_loss: 0.6003 | g_loss: 1.7702
Epoch [ 3/ 50] | d_loss: 0.7450 | g_loss: 1.9247
Epoch [ 4/ 50] | d_loss: 0.9354 | g_loss: 4.2782
Epoch [ 4/ 50] | d_loss: 0.3373 | g_loss: 1.9088
.
.
.
Epoch [ 45/ 50] | d_loss: 0.1435 | g_loss: 4.5801
Epoch [ 46/ 50] | d_loss: 0.0580 | g_loss: 4.6582
Epoch [ 46/ 50] | d_loss: 0.0584 | g_loss: 4.5339
Epoch [ 47/ 50] | d_loss: 0.8925 | g_loss: 5.1713
Epoch [ 47/ 50] | d_loss: 0.0486 | g_loss: 4.5020
Epoch [ 48/ 50] | d_loss: 0.2628 | g_loss: 3.9194
Epoch [ 48/ 50] | d_loss: 0.1131 | g_loss: 4.6293
Epoch [ 49/ 50] | d_loss: 0.1224 | g_loss: 3.1048
Epoch [ 49/ 50] | d_loss: 0.0681 | g_loss: 3.3201
Epoch [ 50/ 50] | d_loss: 0.1082 | g_loss: 2.7829
Epoch [ 50/ 50] | d_loss: 0.0792 | g_loss: 4.2551
# helper function for viewing a list of passed in sample images
def view_samples(epoch, samples):
fig, axes = plt.subplots(figsize=(16,4), nrows=2, ncols=8, sharey=True, sharex=True)
for ax, img in zip(axes.flatten(), samples[epoch]):
img = img.detach().cpu().numpy()
img = np.transpose(img, (1, 2, 0))
img = ((img +1)*255 / (2)).astype(np.uint8) # rescale to pixel range (0-255)
ax.xaxis.set_visible(False)
ax.yaxis.set_visible(False)
im = ax.imshow(img.reshape((32,32,3)))

Final Conclusion
As we can see here that the model is able to generate convincingly enough realistic house numbers. Now had the training been a tad bit longer we could have seen even further development. I stopped it faster to get a result that would be convincing enough for the sake of this article.
Other possible hyperparameter tuning could be rounding up to a better learning rates and beta values. Also to use batch normalization after the activation of relu layer could also have helped.